blog post
Taming Non-Determinism in Agent Systems
Event Sourcing for LLM agents: an immutable log as the single source of truth, deterministic restart, and audit as a side effect of the architecture.
Agent systems don’t break on hard tasks or bad models. They break because of what neural nets fundamentally are: in production they’re non-deterministic. Temperature, model updates, world drift. For anyone trying to build a reliable system, that’s the core problem. How do you debug something that doesn’t reproduce? How do you restart a failed pipeline without starting from scratch? How do you even know what the system is doing if it does it a little differently every time?
One way to live with this is Event Sourcing: a pattern where system state isn’t a snapshot but an immutable log of events. It doesn’t remove the non-determinism — it gives you tools to work with it.
A bit of theory🔗
To be clear up front: the idea isn’t mine and isn’t new. Fowler systematized Event Sourcing in 2005; Greg Young nailed down the ES + CQRS pairing in his 2014 talk. The canonical reading (Vernon, Implementing DDD; Brandolini, Introducing EventStorming) and the tooling (KurrentDB, Axon, Akka Persistence) all live in finance and distributed systems — far from LLMs, but with the exact same three properties of the log. The closest relatives, which reached agents even earlier, are durable execution engines (Temporal, Restate): same “store the event history, replay it deterministically,” just in workflow/activity vocabulary instead of stream/tool_call.
Applying ES directly to LLM agents is a 2026 thing: ESAA (arXiv:2602.23193, the paper that zymi was written under the influence of), OpenKedge (arXiv:2604.08601, which formalizes governance on top of event-sourced state). On the theory side, Intelligent Robotics FAIR 2025 gives eight axioms of auditability, and arXiv:2603.14332 covers cryptographic binding for tamper-evident records. And a separate thread: CoALA (arXiv:2309.02427) and Generative Agents (arXiv:2304.03442, code) already formalized an agent’s episodic memory as an append-only log back in 2023 — meaning the event log and the agent’s memory are the same thing under two names.
Update, July 2026. That memory thread has since grown its own school: Yohei Nakajima’s “The Log is the Agent” (arXiv:2605.21997, the ActiveGraph runtime) makes the record itself the agent, and his July essay derives the same architecture — append-only log, state as a projection over it, replay, forking — from neuroscience. He walks in through the memory door where this article walks in through the reliability one; two independent arguments landing on the same log is the strongest evidence I know that it’s an attractor, not a taste. Where I part ways with the “log is the agent” framing is covered in Compile, don’t emerge.
This is a practitioner essay on top of all that, not a lit review. If you want to dig deeper into any of it: ESAA and OpenKedge for the formalization, FAIR 2025 for the auditability axioms, CoALA and Generative Agents for the link to memory, Temporal and Restate for how this gets solved outside the agent context.
How ESA works🔗
ESA is event-driven architecture with one added invariant: the log is append-only. The event bus isn’t just transport between services — it’s also the single place of truth. Everything that happened in the system lives there and is never edited. Agents on this bus are ordinary subscribers: each waits for the event types it cares about, picks them up, and writes its results back to the same log.
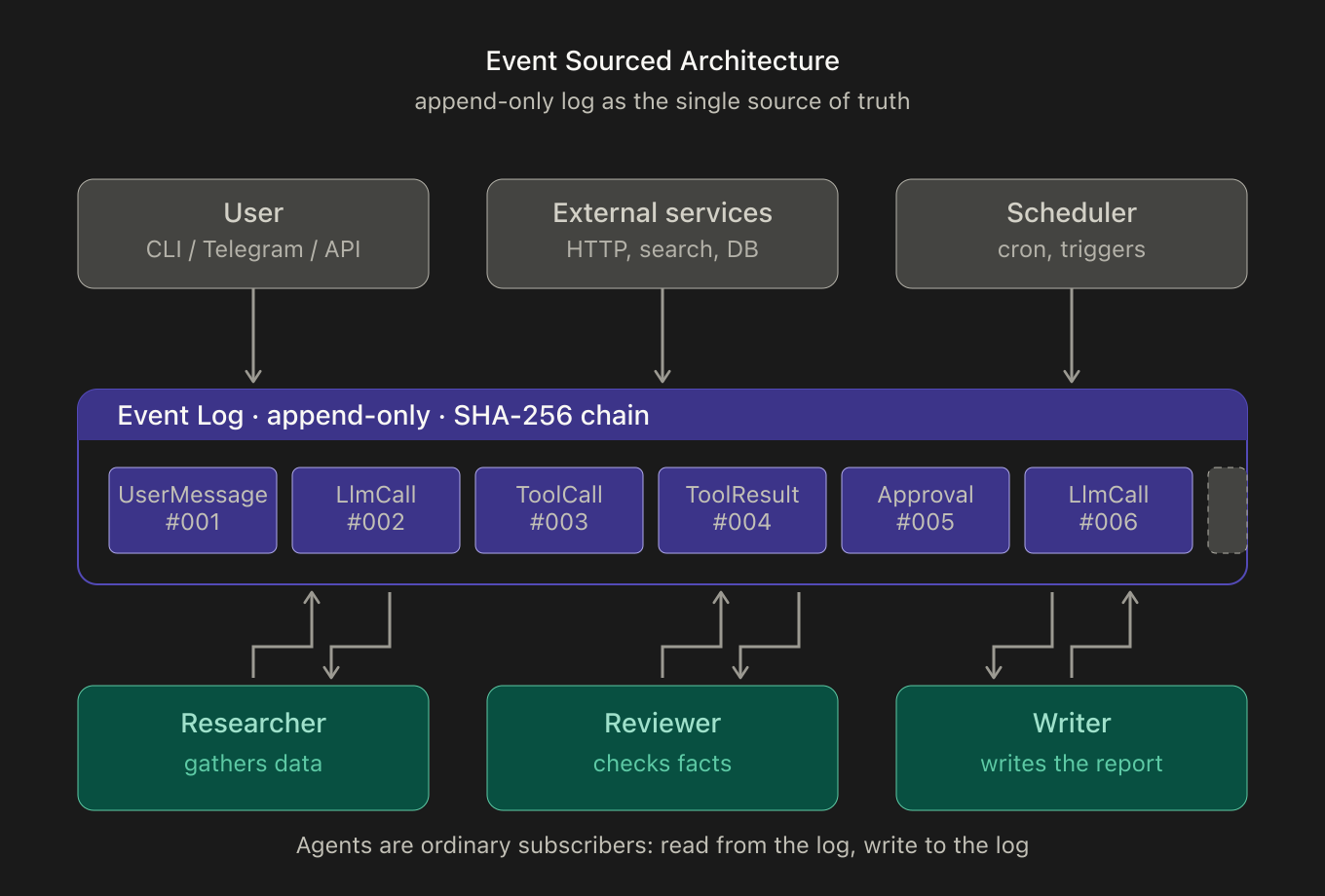
This immutable event log is the most valuable architectural idea in the approach. It buys you several things at once — provided the task fits into events: pipeline restart, a single source of truth, and an immutable, auditable journal. These three are actually one property of the log seen from three angles. Which is exactly why, when any one of them stops being achievable (restart doesn’t reproduce reality, the source of truth lags behind the events, logs have to be “deleted” on request), all three break at once, not just one.
For me personally the pattern became less a ready-made spec and more a good phrasing of a base invariant: the state of an agent system should be derivable from the event journal. From there, zymi raised the more practical questions: how to branch execution, how to avoid repeating external effects, how to assemble context as a projection, and how to make human-in-the-loop part of the same journal.
Restarting a pipeline from any point🔗
ESA lets you do more than restart a pipeline — you can restart it from any arbitrary step. Say you have a research agent that first gathers information and then writes a report from it. If you have a problem with the report-writing step, you can just edit that step and rerun the pipeline from there, without re-gathering the data.

This has the same problems as classic EDA — where EDA had trouble with external events (you can’t charge an account twice on restart) — plus the added non-determinism of the LLM. Fork-resume at least lets you reduce its impact on the final result: you don’t have to re-invoke the agents whose output you were happy with.
In zymi it works roughly like this: zymi resume <stream_id> --from-step writer creates a new stream and physically copies the researcher’s event prefix into it — its LLM calls, its web_scrape results, all of it. The writer restarts with the current prompt from agents/writer.yml; everything else is frozen. External effects inside the re-executed part are handled by a separate flag — if a tool has no_resume: true (e.g. send_email), it isn’t invoked on resume: the journal gets a ToolCallCompleted { replayed: true } with an honest placeholder, and on the next turn the agent sees “this email was already sent earlier, didn’t send it again.”
The log as the single source of truth🔗
The log on its own is fine, but there’s a catch — it only pays off when you make it the single source of truth in the system. Every consumer, every source must interact only through the log. That’s what guarantees both restarts and auditability.
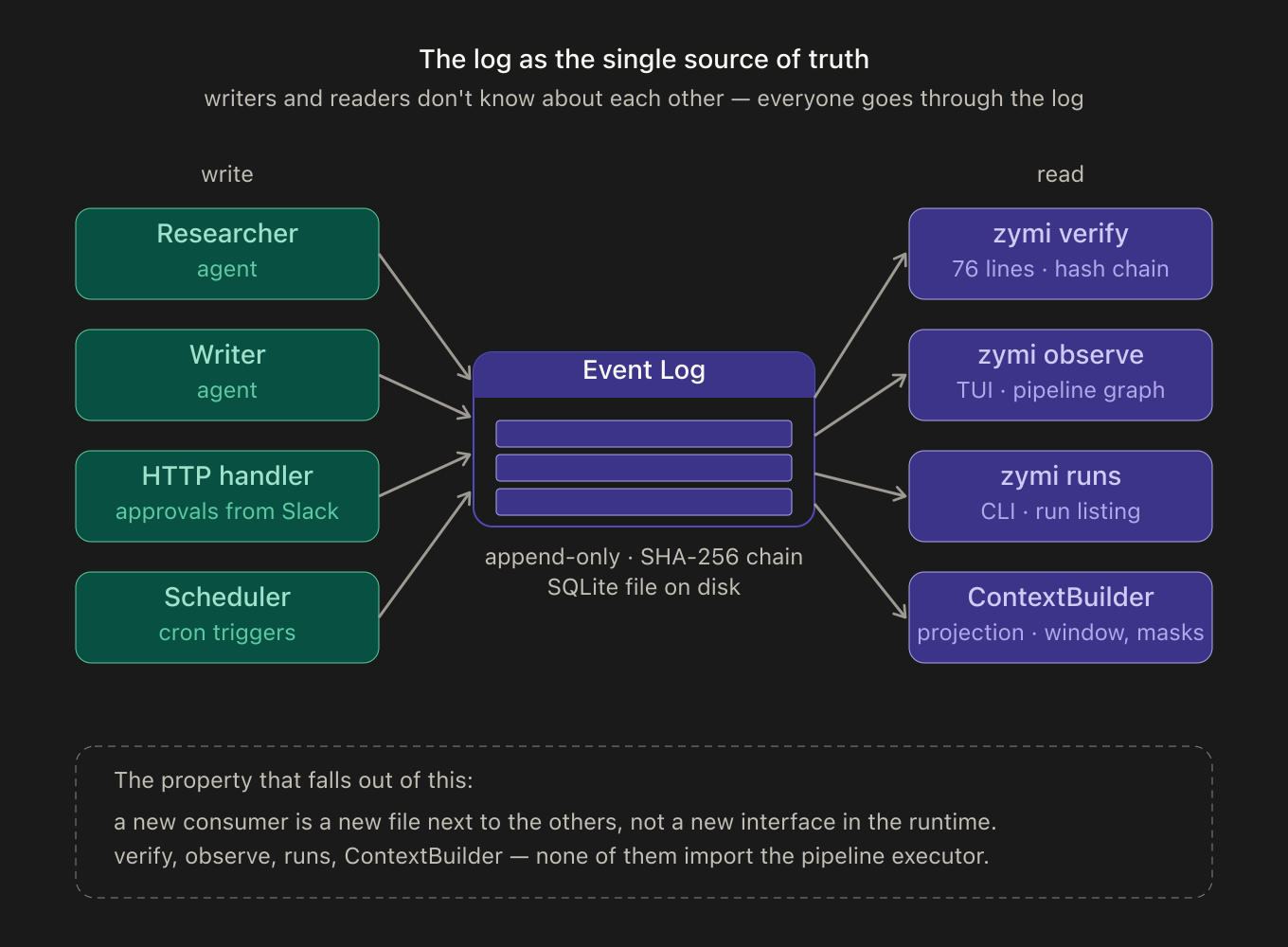
In return, that strict discipline rewards you when wiring in new sources and consumers — you just define a new event type for them to listen to or emit, and that’s it. No extra interfaces; it all works out of the box.
A concrete example from zymi. zymi verify is a command that checks the integrity of the log’s hash chain. When I was adding it, I expected to be wrestling with the runtime: thread hooks in somewhere, don’t break the pipeline executor, don’t disturb the subscribers. In practice it came out as a 76-line file that doesn’t import the runtime at all: it opens the same SQLite, iterates the streams, validates SHA-256. That’s it. zymi observe (a TUI with a live pipeline graph) and zymi runs (a CLI listing of runs) live the exact same way — each command is a standalone consumer on top of one log, and none of them reach into the core. The payoff of a single source is immediate: a new consumer is a new file next to the others, not a new interface in the runtime.
There’s one more upside to a single source of truth: context is no longer a mutable blob in memory, it’s a projection from the log that you can shape however you like. Context window size, the compaction threshold, masking certain results (a big topic of its own — it saves a lot of tokens, and I plan to write it up separately), any manipulation — your hands are completely free, because the originals sit safe and intact in the log. In zymi this is ContextBuilder on top of the same SQLite — bump the window from 10 turns to 30, mask old tool_results with placeholders, rebuild the context for a different agent — all of these are operations on a projection; the originals in the log aren’t touched.
That said, log projections are obviously very hard to scale to millions of events per second, and an event log as the single point of truth is not a great idea for coordinating thousands of parallel agents. Here ESA is powerless and will only add to your headaches.
The immutable, auditable journal🔗
The third face of the same log is immutability. Once we’ve agreed that the log is the single source of truth and all consumers read from it, you only have to demand one thing — “events are only appended, never edited” — and the journal stops being mere storage and becomes an invariant you can check.

Several consequences follow. A hash chain falls naturally onto an immutable log: each record contains SHA-256(event_id || data || prev_hash), and a separate command can walk the stream and tell you whether anything was tampered with — the journal becomes not just immutable by discipline but mathematically verifiable. And the nicest part: the audit trail falls out as a side effect of any new event you put on the bus; you don’t do anything extra for it.
It’s worth calling out that for every event it’s clear where it came from and what caused it. The envelope carries three fields: correlation_id (one user request from start to finish), causation_id (which event produced this one), and source (“cli”, “telegram”, “scheduler”, “agent”). For any fact in the log you can answer “who, when, in response to what” — without a separate audit system, simply because those fields are already in the envelope. For agents this kills the eternal question “why did the model decide that?” — it becomes “show me the chain of events that led to this LlmCallStarted,” and that chain is right there in full, from the original user_message down to the specific tool_result that made it into the context window.
A concrete example from zymi. Human-in-the-loop approvals first lived in a HashMap inside an HTTP handler — ordinary in-memory state under a mutex. Restart the process and you forget who approved what half an hour ago. When we moved approvals onto the bus (ApprovalRequested → ApprovalGranted with a decided_by: "slack:@alice" field), several things got fixed at once: approvals became visible from the TUI, survived restarts, and — as a side effect — a permanent audit trail appeared of “who approved what and when.” Nobody built an audit system separately; it fell out of the fact that approvals now live in the same log as everything else. That’s the “audit is a consequence of the architecture, not a separate feature” property — no longer a slogan, but a specific commit.
The cost here is real too. Data model evolution: the log has accumulated millions of records in the old format over six months, you add a new field, and now you face “what do we do with the old events?” GDPR’s right to be forgotten: an immutable log by definition can’t “forget” one row, and simply erasing it breaks the hash chain. Both problems have working answers:
- For schema,
serde(default)saves you (new fields get defaults, old events read without errors) plus an explicit reduced-precision marker. - GDPR is trickier: a formally immutable journal and the right to be forgotten contradict each other. Two solutions: crypto-shredding — each event with personal data is encrypted with its own key, and on a deletion request you just throw the key away; the event physically stays put but nobody can decrypt it anymore. Or tombstone events — a special record on top that, for all projections, means “forget the previous data about this subject.”
You pay for this in complexity. Projections have to know how to live with old schema versions. And encrypting payloads is a whole key-management infrastructure that you also have to store somewhere and not lose.
Limits of the architecture🔗
It might look like this architecture is a genuine silver bullet for multi-agent systems. Of course it isn’t — like any approach it has its pros and its cons, the ones we’ve already covered along the way:
- Scaling log projections to millions of events is a problem.
- The log as a single point of truth is not a great idea for coordinating thousands of parallel agents.
- The fundamental limit of EDA — a restart doesn’t reproduce what happened on the outside.
- Pain when the event data model evolves.
- An immutable log doesn’t play well with GDPR.
There’s a less obvious cost too: ESA changes the genre of debugging. The familiar “crash → stack trace → line of code” doesn’t work — its place is taken by “crash → find the correlation_id → walk the event chain → reconstruct the state at the moment of failure.” It’s the same difficulty of work, but in a different set of primitives — order, causality, state projection. A team coming from the world of function calls and stack traces needs time to switch lenses; it’s no more expensive than debugging a distributed system, but no cheaper either — just different.
This architecture loses where the nature of the task doesn’t allow you to operate on events: continuous signal streams; data you must be able to delete on demand; thousands of parallel agents with no single coordination point; external services with unpredictable behavior.
A good event-based system knows its boundaries and explicitly steps aside where they’re reached, instead of trying to “event-source everything” by force.
Conclusion🔗
To briefly return to where we started: an immutable log gives you three properties — deterministic restart, a single source of truth, auditability. The key point is that these aren’t three separate perks you can collect independently. They’re one and the same property of the log, turned toward you on three faces. So a compromise on any one of them wrecks the other two: if a restart doesn’t reproduce reality, the log isn’t the source of truth; if a record in the log can be edited, the audit can’t be trusted; if consumers go around the log, fork-resume won’t reproduce the picture they saw.
All the practical cases in this article come from building an open-source framework for agents — zymi-core. I wrote about it in my previous article — What If We Build Agents Like a dbt Project? The project is currently moving toward an MCP server — a backend for agents you can plug into your favorite Claude Code / Codex / OpenClaw and so on.
I also write about agents, Event Sourcing, and adjacent topics on Telegram.
This article was originally published in Russian on Habr